
Most AI agent projects don’t fail loudly. They fail quietly – a demo that impressed the board, a pilot that ran for three months, a Slack channel that went silent. Nobody cancels the project officially. It just stops being mentioned in the roadmap review.
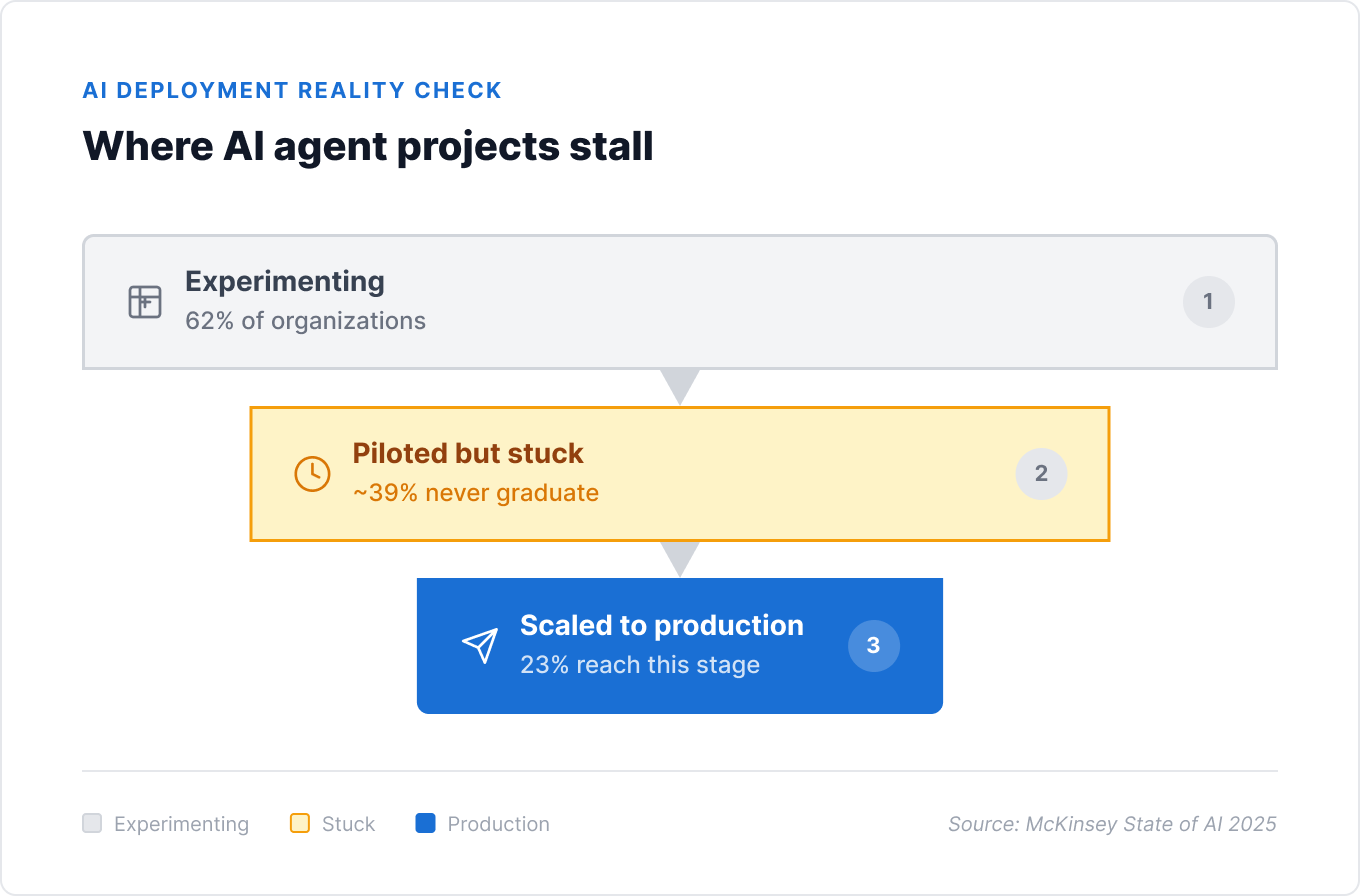
McKinsey’s State of AI 2025 report puts a number on this pattern: 62% of organizations are experimenting with AI agents. Only 23% are actually scaling them. The gap between those two numbers is where most AI budgets quietly disappear.
Gartner’s forecast is more direct still: more than 40% of agentic AI projects will be canceled by the end of 2027 – not because the technology doesn’t work, but because of escalating costs, unclear business value, and inadequate risk controls.
This isn’t a technology problem. It’s a pattern problem. And once you’ve seen it a few times, it becomes predictable.
The pattern: what a stalled pilot actually looks like
Strip away the specifics and most stalled AI agent projects share the same shape.
A team – often IT, sometimes a product manager with enthusiasm and a budget line – builds a proof of concept using an off-the-shelf LLM API. It works in the demo. It answers the questions the team thought to ask. Leadership is impressed. A press release gets drafted, sometimes even sent.
Then it meets production reality. The data the agent needs lives in six different systems, half of them undocumented. The “simple” workflow it was meant to automate actually has fourteen edge cases nobody mentioned in the kickoff meeting. Compliance asks who’s responsible when the agent gets something wrong, and nobody has a clean answer.
Six months later, the pilot is still a pilot. Not because anyone decided to stop – because nobody decided to keep going, either.
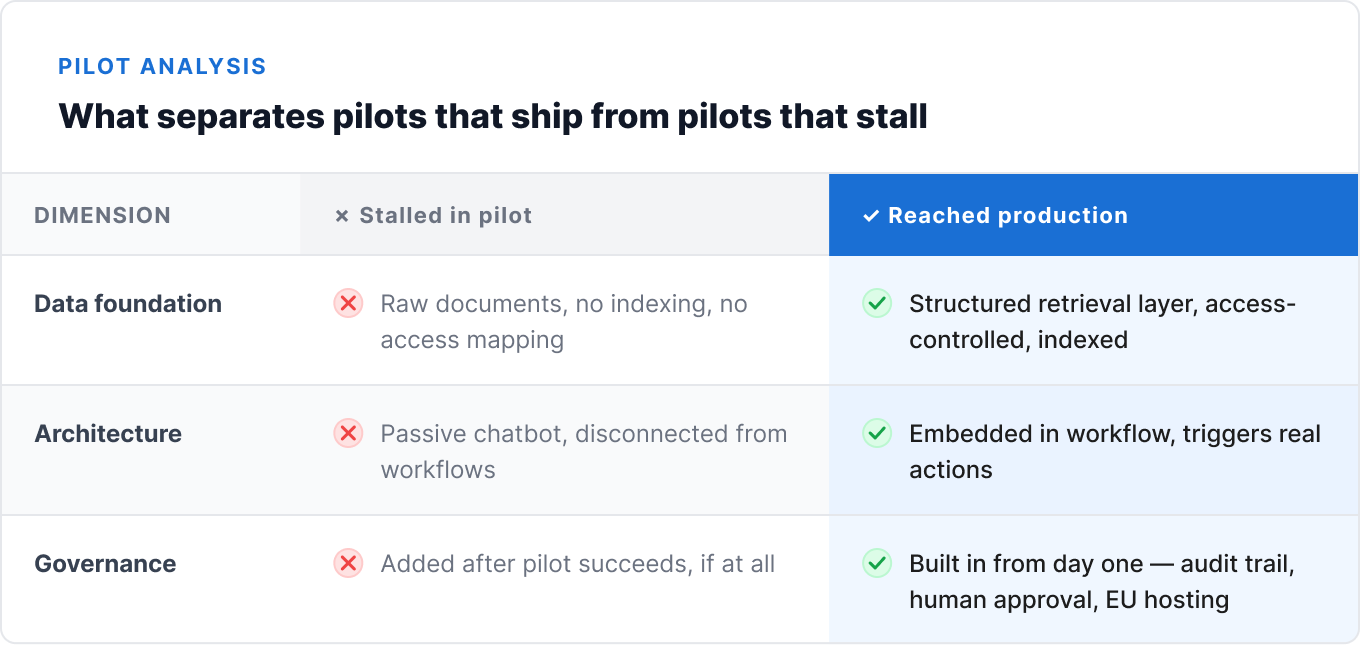
Three things that separate the agents that ship from the ones that get shelved
Across the discovery calls we run with companies evaluating AI agent partners, the same three gaps show up again and again – almost regardless of industry or company size.
1. No organized data foundation
This is the single most common point of failure, and it’s rarely visible until the pilot is already underway.
A team builds a working prototype against a clean, curated dataset – a handful of sample documents, a test database with tidy records. It performs beautifully. Then it’s pointed at the real environment: SharePoint folders with three different naming conventions, an ERP system with inconsistent field formats, contracts scattered across email threads and shared drives with no metadata at all.
The agent isn’t broken. The data foundation underneath it never existed in a form an agent – or honestly, a new employee – could reliably work with.
We’ve had multiple discovery calls with companies that had already run a “first pilot” using a general-purpose LLM API directly against their raw documents, with no retrieval layer, no indexing strategy, and no access control mapping. The pilot looked promising in week one. By week four, the team had quietly stopped trusting its answers.
2. Passive chatbots instead of integrated workflows
The second gap is architectural, not technical. Many first-generation pilots are built as a chat window bolted onto existing systems – a place employees can ask questions, with no real connection to the workflows where decisions actually get made.
This produces a tool people try once, find moderately interesting, and then forget about. It answers questions. It doesn’t do anything – doesn’t trigger an approval, doesn’t update a record, doesn’t flag an exception for review.
The agents that survive into production are designed the opposite way: embedded directly into the workflow, with clearly defined inputs, outputs, and escalation paths. An agent that verifies an invoice and routes it for approval when something looks wrong is solving a different problem than a chatbot that can answer questions about invoices if asked nicely.
3. Governance treated as an afterthought
The third gap shows up later, but it’s often fatal once it does. A pilot that worked fine at small scale runs into a wall the moment legal, compliance, or security asks the obvious questions: Who approved this agent to access this data? What happens when it makes a mistake? Is there an audit trail? Does this comply with GDPR or the EU AI Act?
If those questions get asked for the first time after the pilot has shown promise, the answers usually aren’t ready – and the project stalls while the organization scrambles to retrofit governance onto an architecture that wasn’t designed for it.
Agents built with human-in-the-loop approval, full traceability, and EU-compliant hosting from day one don’t face this wall. They were designed to pass through it from the start.
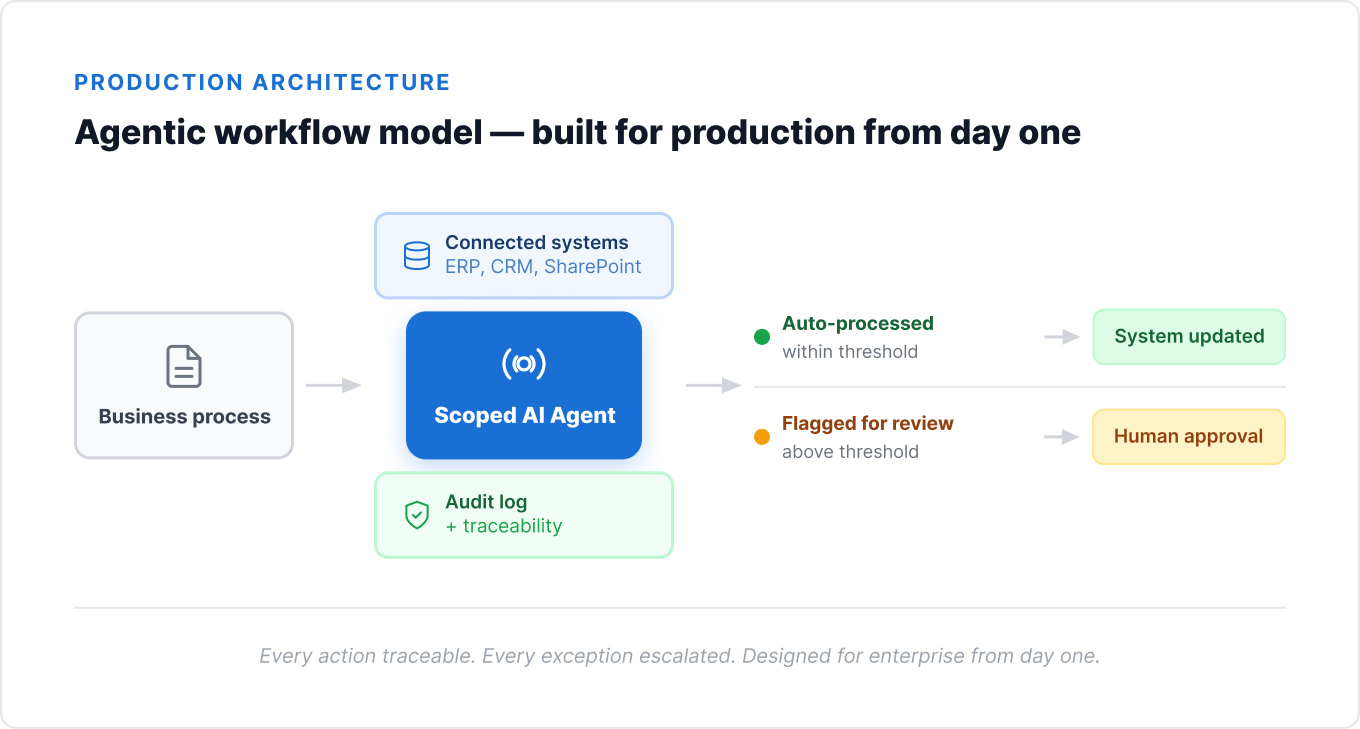
What an agentic workflow model looks like instead
The alternative to the chatbot-bolted-on approach is what we call an agentic workflow model: an agent that’s designed around a specific business process from day one, not retrofitted onto an existing tool stack.
The difference shows up in three concrete ways:
The agent has a defined scope, not an open-ended mandate. Instead of “answer any question about our documents,” the brief is “verify incoming invoices against purchase orders and flag discrepancies above a defined threshold.” Narrow scope means the agent can be evaluated against clear success criteria from week one.
The agent connects to systems, not just to a chat window. It reads from the ERP, writes back to it, triggers a notification when something needs human review. The workflow doesn’t change to accommodate the agent – the agent is built to fit the workflow that already exists.
The agent’s decisions are traceable from the start. Every action is logged. Every escalation includes the reasoning that triggered it. When compliance asks “what happened here and why,” the answer already exists – it doesn’t need to be reconstructed after the fact.
This is also why a four-week proof of concept, scoped correctly, tends to outperform a six-month open-ended pilot. A narrow scope with clear data requirements and a defined success metric either proves the case or rules it out quickly – instead of drifting in pilot purgatory for two quarters before anyone admits it stalled.
Want to see what that process actually looks like end to end? Read our guide to implementing AI automation in your company, including how to choose the right pilot use case and what a realistic 4-to-8-week timeline looks like.
A pattern from the discovery calls – anonymized, but consistent
One pattern that comes up often enough to be worth naming: a mid-sized company runs an initial pilot using a general-purpose LLM API connected directly to their internal documents – no retrieval architecture, no access control layer, no defined escalation path. The pilot demonstrates that “AI can answer questions about our policies.” It does not demonstrate that the answers are reliable, auditable, or scoped to what each employee should actually be allowed to see.
Six months later, the pilot is still a pilot. The company has spent budget and built internal skepticism toward AI as a category – not because the underlying idea was wrong, but because the first attempt was architected as a demo, not as production infrastructure.
When we rebuild these projects, the starting point is rarely “build a smarter model.” It’s “build the data foundation and the governance layer the first version never had” – then scope a narrow, measurable pilot on top of it. The technology was never the bottleneck. The foundation was.
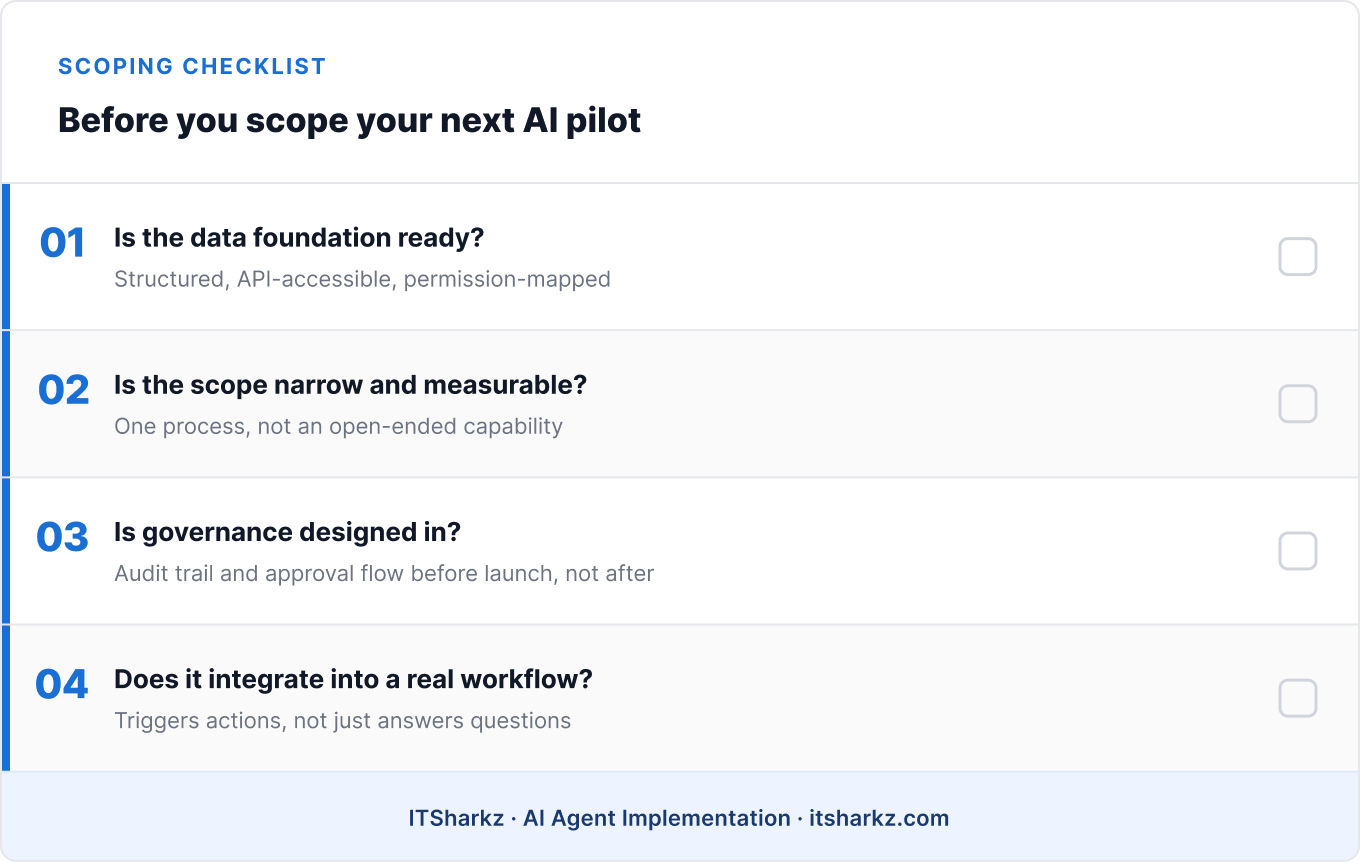
How to avoid pilot purgatory: a practical checklist
Before scoping your next AI agent pilot, four questions are worth answering honestly:
Is the data foundation actually ready? Not “do we have the data somewhere” – is it structured, accessible via API, and mapped to the access permissions that should govern who (or what) can see it?
Is the pilot scoped to a single, measurable process – or to an open-ended capability? “Automate invoice verification for our top 10 vendors” is a pilot. “Make our knowledge base AI-searchable” is a research project wearing a pilot’s clothing.
Is governance designed in, or planned for later? If compliance, legal, and security haven’t reviewed the architecture before the pilot starts, they will review it after – at a much higher cost in time and trust.
Does the agent integrate into a real workflow, or does it just answer questions? If the success metric is “people find it interesting,” that’s a different project than “this reduces processing time by X%.” Only one of those survives a budget review.
If you can’t answer all four clearly, that’s not a reason to abandon the project – it’s the actual starting point. A properly scoped 4-week PoC is designed to answer exactly these questions before committing further budget.
→ See how ITSharkz designs and builds production-ready AI agents – from data foundation to deployment.
Summary
The gap between 62% experimenting and 23% scaling isn’t a technology gap. It’s a foundation gap – in data, in architecture, and in governance.
Three things to remember:
- Most pilots don’t fail because the model is weak. They stall because the data foundation underneath them was never built to support production use.
- A chatbot that answers questions is a different product than an agent embedded in a workflow. Only the second one survives contact with a budget review.
- Governance designed in from day one is faster, not slower. Retrofitting compliance onto an architecture that wasn’t built for it is what actually kills timelines.
If you’re evaluating where to start, our guide to implementing AI automation walks through how to choose the right pilot use case and what a realistic production timeline looks like.
Talk to ITSharkz about scoping a pilot that’s built to reach production – not just to impress a demo audience.
→ Book a meeting