
Jest jedno pytanie, które pojawia się w niemal każdej rozmowie z CTO lub architektem IT, który rozważa wdrożenie agenta AI: „Ale skąd ten agent będzie wiedział, co jest w naszych systemach?”
To właściwe pytanie i przez długi czas nie było na nie dobrej odpowiedzi.
Standardowy model językowy (LLM) wie dużo o świecie – do daty swojego trenowania. Nie wie nic o Twojej firmie. Nie zna Twoich procedur, umów, regulaminów, historii projektów ani aktualnych danych z ERP. Jeśli zapytasz go o dane firmy bez dostarczenia odpowiedniego kontekstu, może odmówić odpowiedzi albo wygenerować treść, która brzmi wiarygodnie, ale nie ma oparcia w źródłach. W środowisku produkcyjnym takie nieuzasadnione lub niezgodne z faktami odpowiedzi są jednym z rodzajów halucynacji.
RAG ogranicza ten problem architektonicznie, dostarczając modelowi odpowiedni kontekst w momencie zapytania, zamiast próbować zapisać aktualną wiedzę firmy w parametrach modelu.
Jak wskazuje analiza ewolucji RAG z połowy 2025 roku, architektura ta przeszła drogę od doraźnego narzędzia redukującego halucynacje do fundamentalnego wzorca budowania wiarygodnych systemów AI w środowiskach enterprise.
Ten artykuł wyjaśnia jak – w języku architekta systemu, nie akademickiego paperu. Jeśli jesteś na etapie oceny, czy agent AI ma w ogóle sens dla Twojej firmy, zacznij od artykułu wprowadzającego o agentach AI. Jeśli już wiesz, że chcesz go wdrożyć, i interesuje Cię, jak podłączyć go do własnych danych – jesteś we właściwym miejscu.
Dlaczego standardowy LLM nie zna Twoich danych firmowych
LLM (Large Language Model) to model wytrenowany na ogromnym zbiorze tekstu z internetu, książek i baz danych – do określonej daty. Jego wiedza jest statyczna. Nie aktualizuje się automatycznie i nie ma dostępu do Twoich systemów.
Trzy konsekwencje, które mają znaczenie w środowisku enterprise:
Wiedza ma datę ważności. Model nie zna Twojego aktualnego regulaminu, najnowszej wersji umowy z kontrahentem ani decyzji zarządu z zeszłego miesiąca. Odpowiedź na pytanie „jaka jest aktualna polityka urlopowa?” będzie albo błędna, albo niemożliwa do udzielenia.
Model nie zna Twoich danych wewnętrznych. Dokumenty, których nie ma w publicznym internecie – wewnętrzne procedury, bazy klientów, historia projektów, dane z ERP – są dla standardowego LLM niewidoczne. Nie ma znaczenia, jak dokładnie zadasz pytanie.
Halucynacje są strukturalnym problemem, nie błędem implementacji. Gdy model nie ma wystarczających informacji, może odmówić odpowiedzi, ale może również wygenerować odpowiedź brzmiącą wiarygodnie, mimo że jest ona nieprawidłowa lub nie ma oparcia w dostępnych źródłach.
Fine-tuning może poprawić sposób wykonywania określonego zadania, format odpowiedzi, zachowanie modelu lub rozumienie specjalistycznego języka. Nie jest jednak optymalnym mechanizmem utrzymywania często zmieniającej się wiedzy firmowej. Jeżeli konkretne fakty zostaną zapisane w parametrach modelu, ich aktualizacja może wymagać kolejnego cyklu treningu i walidacji. RAG dostarcza aktualny kontekst w momencie zapytania bez modyfikowania wag modelu.
RAG rozwiązuje te problemy inaczej.
Jak działa RAG – bez zbędnych uproszczeń
RAG (Retrieval-Augmented Generation) to wzorzec architektoniczny, w którym model językowy otrzymuje dodatkowy kontekst pobrany z zewnętrznego źródła wiedzy. W popularnym wariancie system wyszukuje odpowiednie fragmenty dokumentów za pomocą wyszukiwania wektorowego, tekstowego lub hybrydowego, a następnie przekazuje je modelowi przed wygenerowaniem odpowiedzi.
Sekwencja działania wygląda następująco:
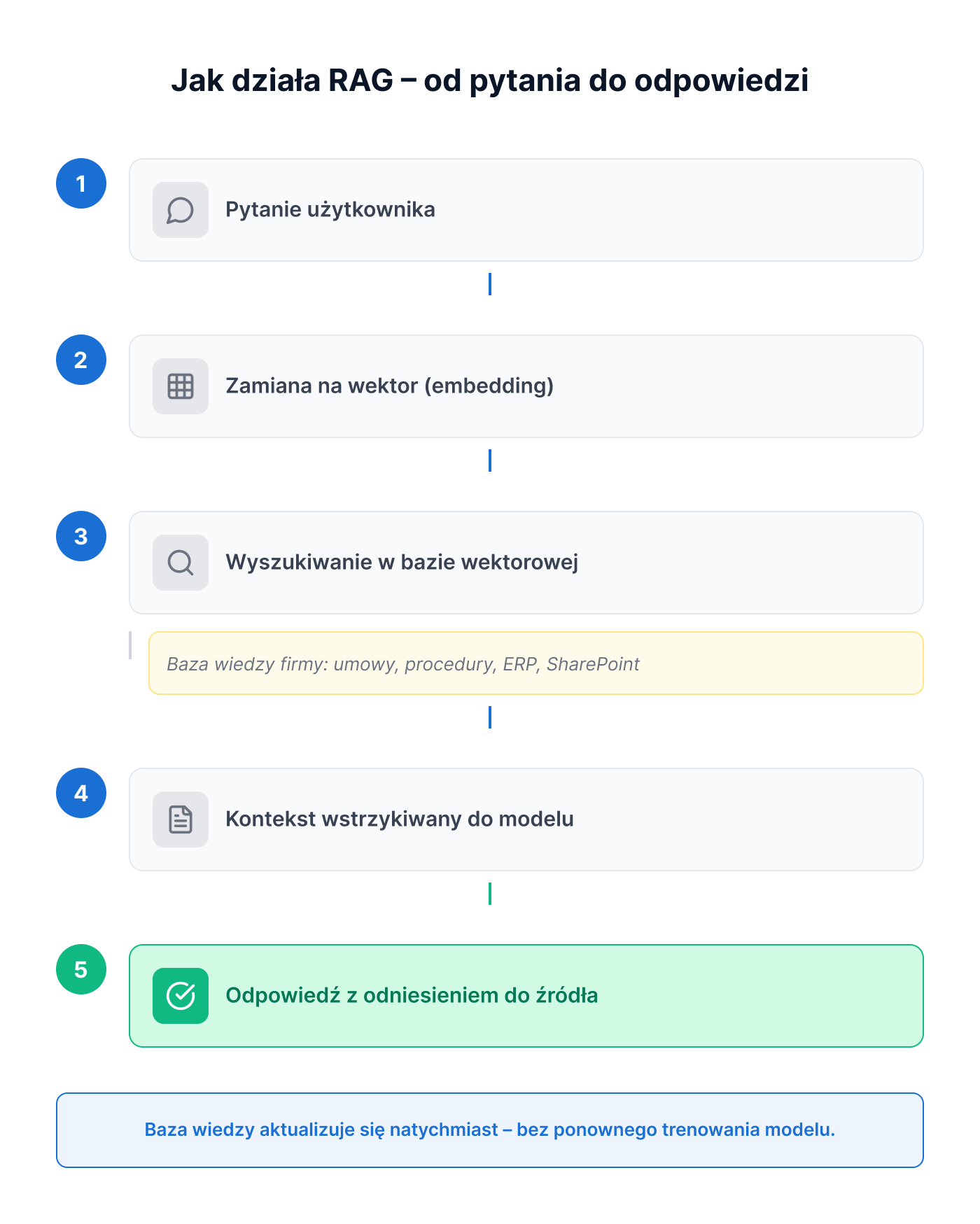
1. Pytanie użytkownika trafia do systemu
„Jakie są warunki gwarancji dla kontraktu z kontrahentem X?”
2. System przygotowuje zapytanie do warstwy wyszukiwania
W przypadku wyszukiwania wektorowego pytanie jest przetwarzane przez model embeddingowy na reprezentację numeryczną. System może również wykorzystać wyszukiwanie tekstowe, filtry metadanych lub podejście hybrydowe łączące kilka metod.
3. Wyszukiwanie odpowiedniego kontekstu
System przeszukuje indeks dokumentów, wykorzystując podobieństwo semantyczne, dopasowanie tekstowe, metadane lub kombinację tych metod. Wyniki mogą zostać dodatkowo uporządkowane przez re-ranking.
4. Kontekst trafia do modelu
Znalezione fragmenty są wstrzykiwane do promptu jako kontekst: „Na podstawie poniższych dokumentów odpowiedz na pytanie…”
5. Model generuje odpowiedź zakorzenioną w danych
Odpowiedź jest generowana z wykorzystaniem pobranych fragmentów dokumentów, ale nadal zależy również od parametrów modelu, instrukcji systemowych i sposobu przygotowania kontekstu. System może wskazać dokument i sekcję źródłową, jednak zgodność odpowiedzi z cytowanym fragmentem powinna być dodatkowo weryfikowana.
Kluczowa różnica: model nie „pamięta” Twoich danych. On je wyszukuje w momencie zapytania. Oznacza to, że nowy regulamin lub umowa mogą być dostępne dla systemu po ich ponownym przetworzeniu, synchronizacji i zindeksowaniu – bez ponownego trenowania modelu. Czas aktualizacji zależy od sposobu integracji źródła, harmonogramu synchronizacji i mechanizmu cache.
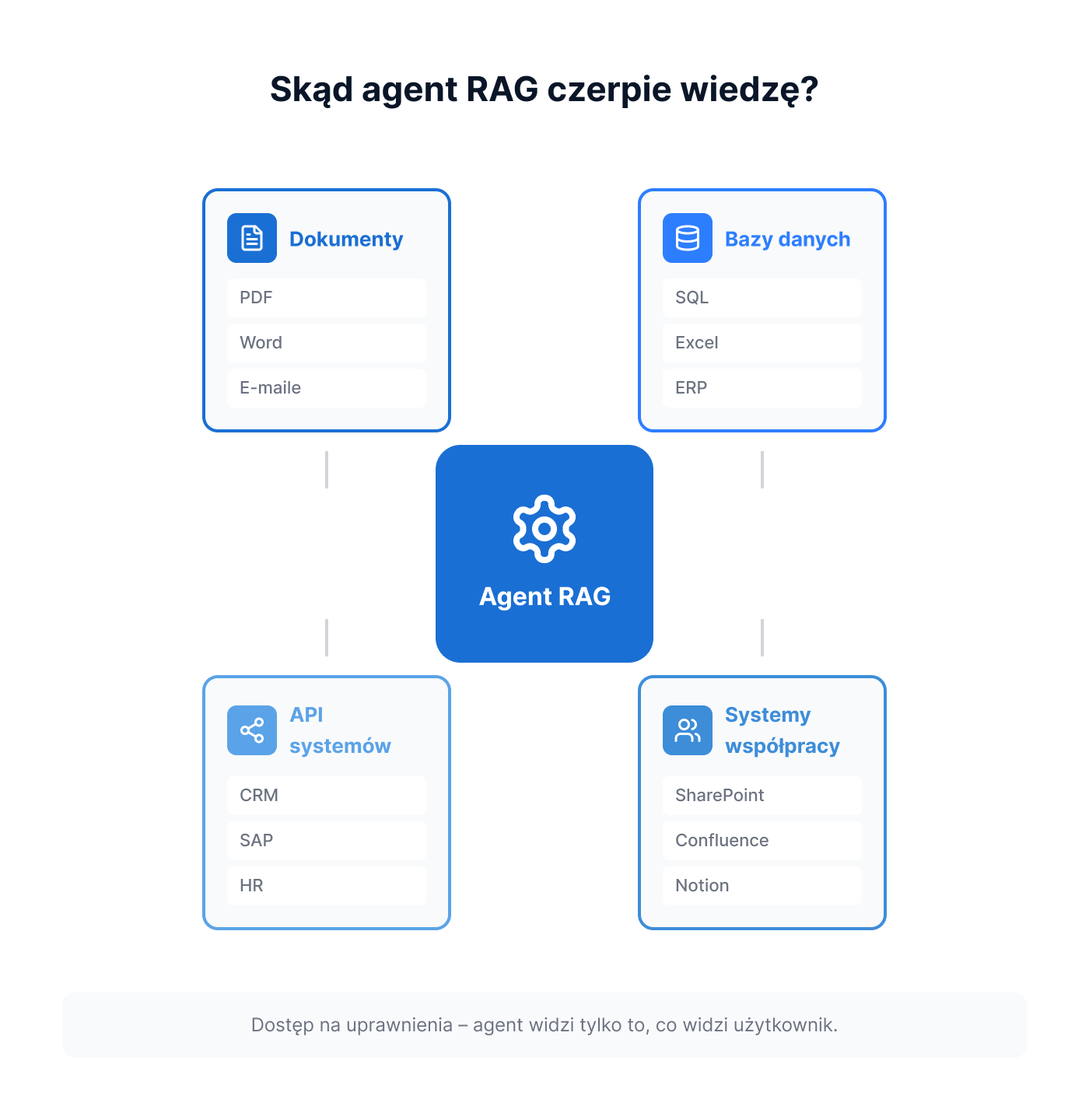
Rodzaje źródeł wiedzy: dokumenty, bazy danych, API, systemy ERP
Warstwa RAG najczęściej odpowiada za wyszukiwanie wiedzy w dokumentach i innych zindeksowanych treściach. W szerszej architekturze agenta może być uzupełniona o narzędzia odpytujące bazy danych, API i systemy operacyjne. Mechanizmy te współpracują ze sobą, ale nie są technicznie tym samym:
Dokumenty niestrukturalne
PDF, Word, PowerPoint, e-maile, transkrypcje spotkań. Wymagają preprocessingu – chunking (podział na fragmenty), ekstrakcja tekstu, indeksowanie. Najczęstszy punkt startowy dla wdrożeń enterprise.
Bazy danych strukturalne
Agent może użyć osobnego narzędzia Text-to-SQL, które generuje i wykonuje kontrolowane zapytanie na podstawie pytania w języku naturalnym i zwracać dane liczbowe lub agregowane. Przykład: „Jaki był średni czas realizacji zamówień w Q1?” – agent zapytuje bazę danych sprzedażowej.
API systemów wewnętrznych
CRM (Salesforce, HubSpot), ERP (SAP, Comarch, Microsoft Dynamics), systemy HR, ticketingowe. Agent może odpytywać API w momencie realizacji zapytania, dzięki czemu korzysta ze stanu danych dostępnego w systemie źródłowym. Ich aktualność nadal zależy od jakości danych źródłowych, cache, opóźnień synchronizacji i dostępności integracji.
Systemy współpracy
SharePoint, Confluence, Notion, Google Drive. Dokumentacja projektowa, wiki wewnętrzne, procedury operacyjne. Wymagają odpowiedniego zarządzania uprawnieniami – agent powinien widzieć tylko to, do czego dany użytkownik ma dostęp.
Złota zasada projektowania: zacznij od jednego, dobrze ustrukturyzowanego źródła. Próba podłączenia wszystkich systemów jednocześnie w pierwszym wdrożeniu to jeden z najczęstszych błędów, który prowadzi do niskiej jakości odpowiedzi i trudnej diagnostyki.
RAG vs. fine-tuning – co wybrać i kiedy
To jedno z najczęściej zadawanych pytań przez CTO przed podjęciem decyzji architektonicznej. Odpowiedź zależy od tego, czego potrzebujesz.
RAG jest właściwym wyborem gdy:
- Twoje dane zmieniają się regularnie (nowe umowy, aktualizacje procedur, nowe dane z systemów) – RAG nie wymaga ponownego trenowania przy każdej zmianie
- Potrzebujesz możliwości śledzenia źródeł odpowiedzi – system RAG może zwracać dokumenty i fragmenty wykorzystane podczas generowania, pod warunkiem że mechanizm provenance i cytowania został prawidłowo zaimplementowany i przetestowany
- Dane są wrażliwe i nie powinny być wykorzystywane do aktualizacji parametrów modelu. Należy jednak pamiętać, że fragmenty pobrane przez RAG mogą być przekazywane do modelu podczas inferencji, dlatego trzeba zweryfikować sposób hostowania, retencję danych, warunki dostawcy i lokalizację przetwarzania.
- Chcesz szybko wdrożyć i iterować – PoC z RAG można postawić w tygodnie, nie miesiące
- Zakres pytań jest szeroki i trudny do przewidzenia z góry
Fine-tuning ma sens gdy:
- Chcesz zmienić styl, ton lub format odpowiedzi modelu (np. zawsze odpowiada jak ekspert prawny)
- Masz bardzo specyficzne zadanie z dobrze zdefiniowanym zestawem danych treningowych
- Potrzebujesz poprawić rozumienie specjalistycznego żargonu branżowego przez model
- Dysponujesz budżetem na trenowanie i infrastrukturą do jego utrzymania
Szczegółowe porównanie obu podejść z perspektywy enterprise, w tym kwestii kosztów, governance i czasu wdrożenia, znajdziesz w enterprise guide Matillion: RAG vs fine-tuning.
W praktyce: RAG + fine-tuning razem
RAG i fine-tuning mogą się uzupełniać: fine-tuning dostosowuje zachowanie modelu do konkretnego zadania, a RAG dostarcza aktualny kontekst z firmowych źródeł. Połączenie obu podejść ma sens wtedy, gdy testy pokażą, że sam RAG nie zapewnia wymaganej jakości.
W przypadku firmowych systemów Q&A, wyszukiwania dokumentów i wiedzy, która regularnie się zmienia, RAG jest często rozsądnym pierwszym krokiem. Potwierdza to analiza Monte Carlo AI: RAG jest generalnie lepszym wyborem dla środowisk enterprise ze względu na bezpieczeństwo, skalowalność i koszt utrzymania. Ostateczny wybór powinien jednak wynikać z testów jakości, wymagań bezpieczeństwa, wolumenu zapytań, kosztów i oczekiwanych czasów odpowiedzi.

Jak zminimalizować halucynacje agenta AI w środowisku produkcyjnym
RAG może istotnie ograniczyć halucynacje, ale ich nie eliminuje. Błędy mogą wynikać z nieaktualnych dokumentów, nieprawidłowego podziału treści, słabego wyszukiwania, niewłaściwego rankingu wyników albo z tego, że model błędnie zinterpretuje poprawnie pobrany kontekst. Dlatego jakość systemu zależy zarówno od danych, jak i od całego pipeline’u retrievalu i generowania.
Pięć praktyk, które stosujemy przy każdym wdrożeniu produkcyjnym:
1. Zamknięta baza wiedzy, nie otwarty internet
Agent powinien odpowiadać wyłącznie na podstawie zindeksowanych dokumentów firmowych – nie sięgając do internetu. Jeśli odpowiedź nie ma podstawy w bazie, agent powinien powiedzieć „nie znalazłem odpowiedzi w dostępnych dokumentach” – nie wymyślać.
2. Chunking z zachowaniem kontekstu
Podział dokumentów na fragmenty (chunks) to kluczowy krok preprocessing. Zbyt małe fragmenty tracą kontekst. Zbyt duże obniżają precyzję wyszukiwania. Dla dokumentów proceduralnych zakres 300–600 tokenów może być użytecznym punktem startowym, ale nie jest uniwersalnym optimum. Wielkość fragmentów, overlap i sposób podziału powinny być dobrane na podstawie struktury dokumentów oraz testów retrievalu na reprezentatywnym zestawie pytań.
3. Retrieval z re-rankingiem
Pierwsze wyszukiwanie wektorowe zwraca kandydatów. Re-ranker, na przykład cross-encoder, ponownie ocenia trafność kandydatów względem pytania i zmienia ich kolejność. Może ograniczyć udział słabych dopasowań w kontekście, ale nie gwarantuje, że wszystkie nieistotne fragmenty zostaną usunięte.
4. Walidacja odpowiedzi przed zwróceniem
W krytycznych procesach (weryfikacja dokumentów finansowych, odpowiedzi na pytania prawne) odpowiedź agenta powinna przejść przez dodatkowy krok walidacji – czy jest zakorzeniona w cytowanych fragmentach źródłowych, czy nie zawiera informacji spoza kontekstu.
5. Monitoring i feedback loop
System rejestruje niezbędne metadane, wyniki retrievalu, eskalacje oraz oceny użytkowników. Treść zapytań powinna być logowana wyłącznie w zakresie potrzebnym do monitoringu, z uwzględnieniem maskowania danych osobowych, kontroli dostępu i ustalonego okresu retencji. Analiza ocen negatywnych pozwala identyfikować słabe punkty systemu i poprawiać je iteracyjnie.
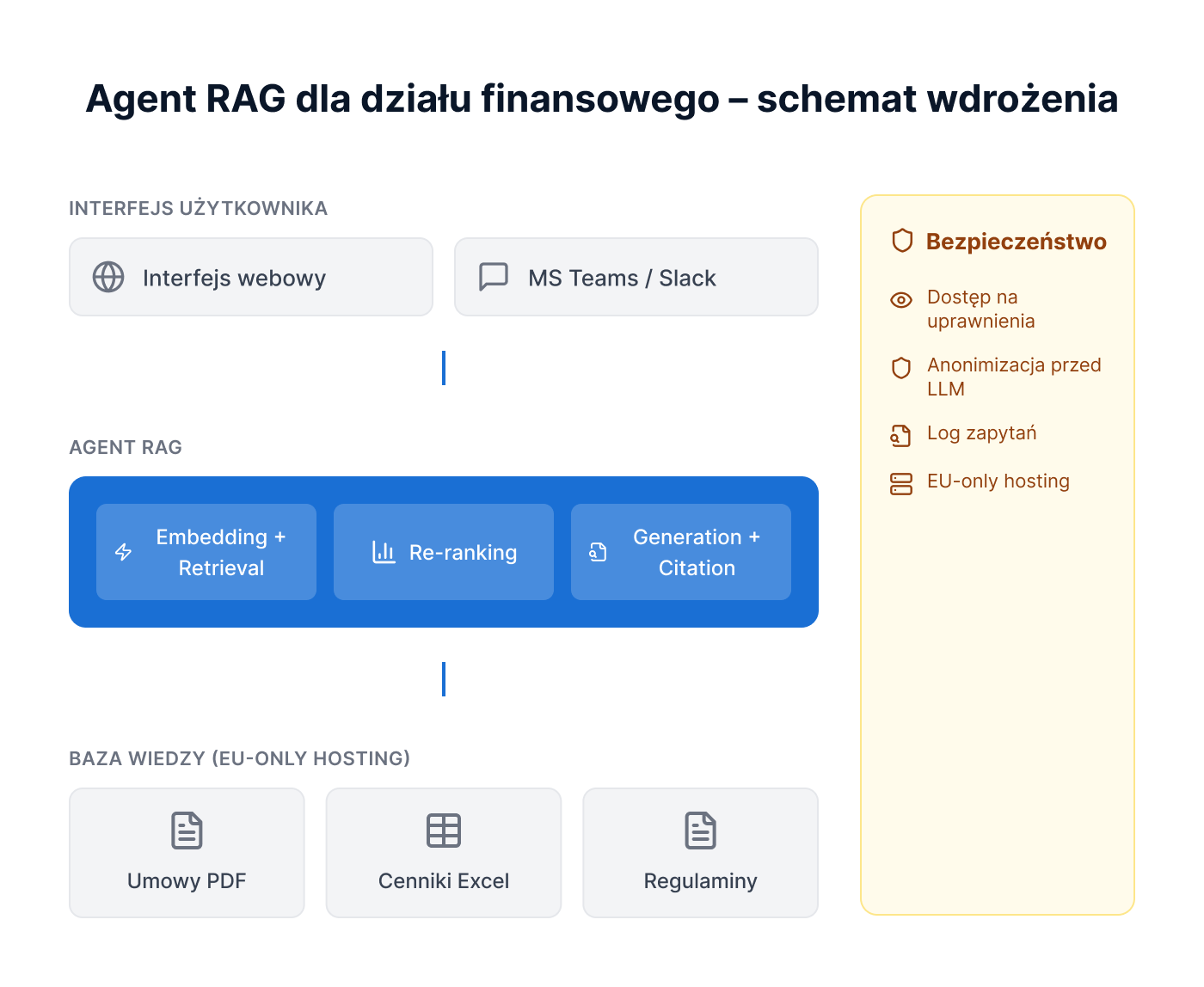
Przykład architektury: agent RAG dla działu finansowego
Żeby nie mówić abstrakcyjnie – pokażemy to na konkretnym przypadku z naszych wdrożeń.
Jeden z naszych partnerów potrzebował agenta AI, który odpowiada na pytania dotyczące warunków umów z kontrahentami – stawek, terminów płatności, zapisów dotyczących kar umownych. Dotychczas każde takie pytanie wymagało przeszukania archiwum umów lub zapytania do prawnika.
Architektura wdrożenia:
→ Źródła wiedzy: archiwum umów w formacie PDF (kilkaset dokumentów), aktualny cennik usług w formacie Excel, regulamin wewnętrzny działu finansowego.
→ Pipeline: dokumenty są preprocessowane (OCR dla skanów, ekstrakcja tekstu), dzielone na fragmenty z metadanymi (numer umowy, kontrahent, data), indeksowane w bazie wektorowej hostowanej na infrastrukturze EU-only.
→ Zapytanie: użytkownik pyta w naturalnym języku przez interfejs webowy lub integrację z MS Teams. Agent wyszukuje odpowiednie fragmenty, generuje odpowiedź i zwraca ją z odniesieniem do konkretnej umowy i sekcji.
→ Bezpieczeństwo: dostęp zgodny z uprawnieniami użytkownika, minimalizacja i tam, gdzie to możliwe, pseudonimizacja danych przed przekazaniem ich do modelu oraz kontrolowany log audytowy z określonym zakresem i okresem retencji.
Efekt: czas uzyskania odpowiedzi na pytanie o warunki umowy – z kilkudziesięciu minut (szukanie w archiwum lub czekanie na odpowiedź prawnika) do kilkunastu sekund. Każda odpowiedź weryfikowalna – powiązana ze źródłowym dokumentem.
→ Sprawdź, jak ITSharkz projektuje i wdraża agentów AI
Podsumowanie
RAG nie jest modą. Jest odpowiedzią na fundamentalne ograniczenie standardowych modeli językowych w środowisku enterprise – brak dostępu do aktualnych, firmowych danych.
Trzy rzeczy, które warto zapamiętać:
- RAG dostarcza modelowi kontekst z firmowych źródeł. Ogranicza to ryzyko odpowiedzi nieopartych na danych, ale nie usuwa go całkowicie – system nadal wymaga testów retrievalu, zgodności odpowiedzi ze źródłami i obsługi sytuacji, w których nie znaleziono wystarczających informacji.
- RAG nie wymaga wykorzystywania dokumentów do aktualizacji parametrów modelu, ale pobrane fragmenty mogą być przetwarzane przez model podczas inferencji. Bezpieczeństwo zależy więc od architektury, sposobu hostowania, kontroli uprawnień, warunków dostawcy i zasad retencji danych.
- Jakość RAG zależy od jakości danych. Chaotyczne i nieaktualne dokumenty są jednym z głównych źródeł problemów, ale jakość rozwiązania zależy również od chunkingu, wyszukiwania, rankingu, instrukcji dla modelu, kontroli dostępu i procesu ewaluacji.
Jeśli zastanawiasz się, jak RAG wpisuje się w szerszy plan automatyzacji procesów w Twojej firmie, przeczytaj przewodnik po wdrożeniu automatyzacji AI – w tym jak wybrać właściwy przypadek pilotażowy i jak wygląda timeline od warsztatu do produkcji. A jeśli widzisz zastosowanie RAG konkretnie w obszarze HR i knowledge managementu, sprawdź artykuł o automatyzacji HR z AI.
Omów architekturę swojego agenta AI z zespołem ITSharkz.
→ Umów bezpłatny warsztat